Jennifer L. Schenker, blogde op Medium over ‘Knowledge Graphs’ (KG’s). Het leuke plaatje met gekleurde ballen en lijnen in haar blog trok onmiddellijk mijn aandacht. KG’s worden gebruikt om relaties tussen data te beschrijven met behulp van objecten, onderwerpen en relaties. De denkwijze hierachter is dat data niet in silo’s van individuele bedrijven thuishoren en moeten worden getransformeerd of hernoemd om gebruikt te worden in combinatie met data van andere bedrijven.
Google gebruikt Knowledge Graphs voor het combineren van zoektermen naar de juiste zoekresultaten. Dit wordt uitgelegd in bovenstaand filmpje.
De simpelste vorm van een KG (Knowledge Graph) bevat een onderwerp of object (‘node’), en een relatie (‘edge’) hiervan met een ander onderwerp of object.

Bijv. ‘Leonard Nimoy was een acteur die dr. Spock speelde in de science fiction film Star Trek’. Bij het opstellen van KG wordt gewerkt met tripletten die bestaan uit een onderwerp (‘subject) en een object (‘object’); (de entiteiten) en het predicaat (‘predicate’) (de relatie) dat hierop van toepassing is.
| Onderwerp (‘Subject)’ | Predicaat (‘Predicate’) | Object (‘Object’) |
| Leonard Nimoy | beroep | acteur |
| Leonard Nimoy | speelde in | Star Trek |
| Spock | karakter in | Star Trek |
| Star Trek | film genre van | Science Fiction |
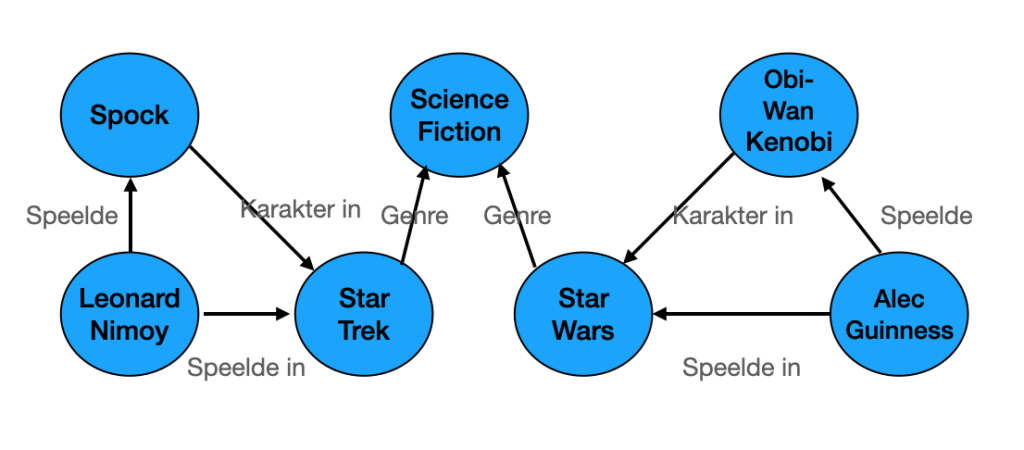
Knowledge graphs kunnen worden samengesteld uit datasets van verschillende bronnen, die eveneens verschillen in structuur. Die structuur wordt bepaald door het framework voor de KN. Schema’s bepalen de structuur voor de KG. Bekijk bijv. aan de bovenstaande afbeelding.
Wikidata, dat o.a. Wikipedia van informatie voorziet is een voorbeeld van een wereldwijd toepasbaar KG. De dataset van Wikidata bestaat uit meerdere bronnen zoals het Amerikaanse ‘ Library of Congress’ Het heeft data voorzien van labels en brengt relaties aan tussen data. Deze worden beheerd in een aparte structuur. Hiermee wordt het mogelijk om via zoektermen in deze structuur relaties tussen entiteiten te laten zien én deze toe te passen op verschillende databases die via Wikidata worden beheerd. Bijvoorbeeld ‘opleidingsinstituut’
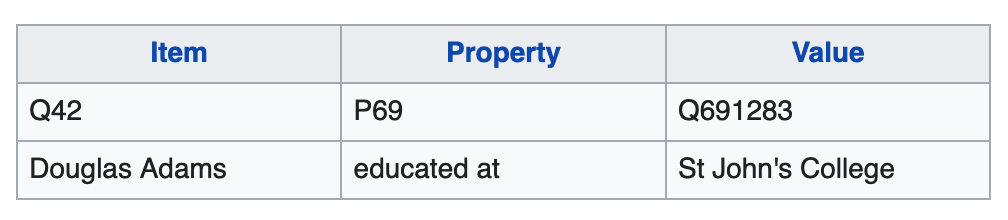
De ‘Wiki’ van Douglas Adams:
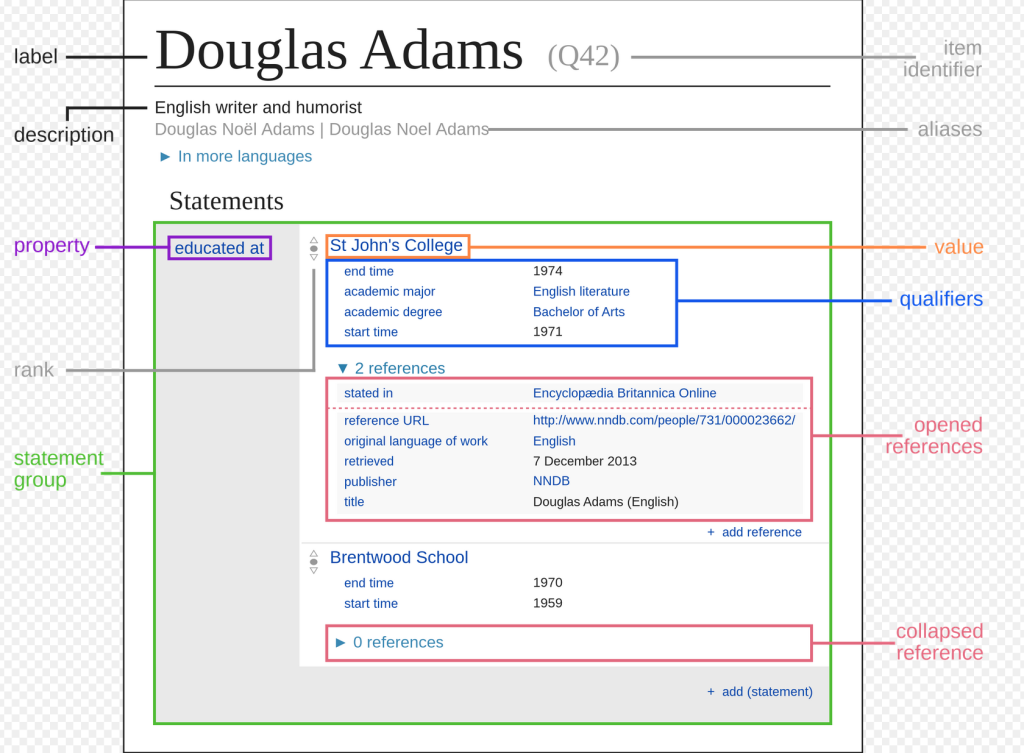
In de afgelopen jaren is veel vooruitgang geboekt bij het ‘automatiseren’ van de herkenning van relaties tussen onderwerpen en objecten. Natural Language Processing (NLP) maakt het mogelijk om entiteiten (onderwerpen en objecten) en hun relaties af te leiden uit teksten en deze met elkaar in verband te brengen. Hierbij worden de regels voor het herkennen van relaties toegepast in computerprogramma’s (‘machine learning’) waarmee de relaties kunnen worden vastgesteld. Het gebruik van KG’s vormt de basis voor NLP’s.
Wanneer relaties voor specifieke onderwerpen of thema’s worden vastgesteld, zoals in de geneeskunde, kunnen KG’s worden vastgesteld. Dit is bijv. het geval bij het UMLS, het ‘Unified Medical Language System’ van het US National Library of Medicine network. Dit definieert 134 onderwerp categorieën, entiteit types, en 54 relaties tussen the entiteiten, zoals de volgende vertaling:
| Entiteit | Relatie | Entiteit |
| Verwonding | Verstoort | Fysiologische functie |
| Locatie in het lichaam | Locatie van | Biologische functie |
| Anatomische structuur | Deel van | Organisme |
| Farmacologische substantie | Veroorzaakt | Pathologische functie |
| Farmacologische substantie | Behandelt | Pathologische functie |
De zin “Doppler echocardiografie kan worden gebruikt om voorste linker aflopende arterie stenose te diagnosticeren bij patienten met type 2 diabetes” kan via een schema worden teruggebracht tot ” Echocardiografie, Doppler Diagnose Verworven aandoening” (https://web.stanford.edu/~jurafsky/slp3/17.pdf)
Vergelijkbaar met het UMLS is ‘schema.org‘ van techgiganten Google, Yahoo, Yandex en Microsoft. Hiermee wordt informatie op het web voorzien van gestandaardiseerde kenmerken over informatie bij het opmaken van tekst ten behoeve van het opzoeken ervan via zoekmachines. Het gaat dus niet meer om afspraken door de medische beroepsgroep, maar afspraken over meta-informatie op het web. Er worden hier vooraf afgesproken kenmerken toegevoegd die specifiek zijn voor het onderwerp van een webpagina. Bijv. een pagina over de diagnose ‘Covid-19’ krijgt als toevoeging in de opmaak het kenmerk voor de internationaal vastgestelde diagnose code mee zodat dit vindbaar is in de zoekmachines. Voor de behandeling van Covid-19 wordt vervolgens een ander kenmerk toegevoegd.
Bronnen:
- https://www.ibm.com/cloud/learn/knowledge-graph#toc-how-a-know-0rYVxiNb
- http://Knowledge Graphs: An Overview
- https://medium.com/analytics-vidhya/a-knowledge-graph-implementation-tutorial-for-beginners-3c53e8802377
- https://ai.stanford.edu/blog/introduction-to-knowledge-graphs/
- https://web.stanford.edu/~jurafsky/slp3/17.pdf
Meer informatie.
https://medium.com/vectrconsulting/build-your-own-knowledge-graph-975cf6dde67f

Dit werk valt onder een Creative Commons Naamsvermelding-NietCommercieel 4.0 Internationaal-licentie.




